
Les Pratiques SRE Et Le Climat
Table des matières
L’ingénierie de la fiabilité des sites (Site Reliability Engineering), a pour objectif au sein d’une organisation de s’assurer que les systèmes et services logiciels qui y sont créés sont évolutifs et surtout très fiables.
Pour ce faire, de nombreux aspects de l’ingénierie logicielle sont appliqués aux problèmes d’infrastructure. Ce sont des pratiques mises en avant par Google, notamment depuis la sortie du premier livre “référence” intitulé “Site Reliability Engineering” en 2016.
DevOps, SRE, quelle différence ?
Puisque nous avons mis un pied dans le dangereux royaume des buzzwords, tentons d’y voir plus clair avant de continuer. Si vous êtes déjà familiers avec le DevOps et les pratiques SRE, vous pouvez passer directement à la suite de cet article.
Le cadre de travail SRE a quelques points communs avec le mouvement DevOps, notamment :
- Le changement est nécessaire pour s’améliorer: adopter les méthodes DevOps ou les pratiques SRE, c’est l’inverse du cycle en V et des gels de déploiements sur une infrastructure. Dans les deux cas, identifier les axes d’amélioration, faire des changements et apprendre de ses erreurs, est essentiel pour atteindre plus de vélocité (DevOps), de qualité et de fiabilité (SRE).
- Casser les silos : contrairement au monde décrit dans IT crowd, les pratiques DevOps comme SRE encouragent une collaboration régulière et systématique entre les développeurs, le produit et l’infrastructure, à chaque étape d’un projet. La littérature SRE parle même de “shared ownership model” ou modèle de responsabilité partagée. Dans ce contexte, les responsables produit sont tout autant responsables (et donc investis) que les développeurs ou que les SRE, lors de la mise en place d’un changement dans un service ou une application.
- De petits changements, fréquents sont préférés à de grosses mises à jour issues de plusieurs mois de développements. Ceci permet une plus grande fiabilité, en particulier si chacun d’entre eux est testé automatiquement, ce qui contribue à la feedback loop.
- Un incident ou un échec n’est jamais la faute d’une seule personne : il convient donc de comprendre l’explication systémique d’un problème (le bouton dangereux dans l’interface X n’est pas assez rouge et on ne demande pas à l’utilisateur Michel s’il est sûr de lui), plutôt que de chercher un coupable (c’est la faute de Michel).
Les deux mouvements sont donc très proches, si bien que certains considèrent que SRE est une implémentation de la méthode DevOps qui prend en compte les problématiques d’infrastructure. On pourra souligner que contrairement à DevOps, SRE peut être un métier en tant que tel (Site Reliability Engineer), là où DevOps est seulement un mouvement, ou un ensemble de bonnes pratiques.
SLI, SLO et le budget d’erreur
Je souhaite vous parler aujourd’hui d’un élément particulier parmi les pratiques SRE : les fameux SLI et SLO, pour Service Level Indicators et Service Level Objectives. Ces notions donnent un cadre pour déterminer quelles métriques sont importantes pour la réussite d’un projet dans sa phase de run.
Un Service Level Indicator est le plus souvent un ratio entre deux nombres. L’un étant le nombre d’événements “positifs”, l’autre le nombre total d’événements correspondants. Quelques exemples de SLI:
- nombre de requêtes HTTP soldées par un succès / nombre total de requêtes HTTP sur le même service
- nombre de demandes sur mon datastore, qui ont retourné un résultat en moins de 2 secondes / nombre total de demandes sur le datastore
- nombre d’appels gRPC qui ont terminé en moins de 80ms / nombre total d’appels gRPC sur le même service
Un point important pour bien choisir un SLI est qu’il doit permettre de mesurer la satisfaction d’un client ou d’un utilisateur (humain ou machine). C’est pour ça que l’on va souvent s’intéresser aux notions d’erreurs perçues par le client ou de latence, plutôt que de savoir quelle quantité de mémoire est utilisée sur le serveur, par exemple.
La deuxième notion importante ici est le Service Level Objective. Il s’agit ni plus ni moins que d’un objectif à atteindre sur un SLI, sur une fenêtre de temps flottante ou basée sur le calendrier (chaque mois par exemple). Cet objectif doit être défini conjointement entre l’équipe produit, l’équipe en charge de l’environnement de production et les développeurs. Le respect de cet objectif doit également être porté/assumé par une personne ayant suffisamment de “pouvoir” pour faire des compromis entre la vélocité (la vitesse à laquelle les fonctionnalités sont déployées) et la fiabilité. Ce peut donc être le CTO si c’est une petite organisation ou le product owner/manager, dans une structure plus conséquente.
La différence entre 100% (de cas positifs pour le SLI) et le SLO (disons par exemple 97% de requêtes dont la réponse prend moins de 50 ms de latence) est appelée le budget d’erreur (error budget). Si le nombre de cas “négatifs” (dommageables pour la réalisation du SLO) fait tomber le SLI en dessous du SLO sur la période, on a épuisé notre budget d’erreur. Dans ce cas il faut, soit revoir la conception ou l’implémentation technique du service pour respecter le SLO sur la prochaine période, ou bien redéfinir le SLO si l’on se rend compte qu’il était trop ambitieux (un SLO de 100% est rarement une bonne idée).
Vous vous en doutez, un monitoring adéquat et la mise en place d’alertes lorsque le budget d’erreur est entamé ou menacé sont nécessaires. Ces indicateurs deviennent un point d’attention central des équipes de développement, de production, mais aussi de l’équipe produit. On pourra par exemple mettre en place un dashboard faisant état des SLI et de l’état de consommation des budgets d’erreur sur le mois, qui sera accessible de toutes les équipes concernées.
L’intérêt de cette méthode est qu’elle encourage les équipes produit, infrastructure et de développement à collaborer autour d’un même objectif, à savoir dans la plupart des cas, la satisfaction utilisateur.
Une fois ces principes appliqués à plusieurs services/produits numériques de l’organisation, il est possible de générer un dashboard montrant si les SLO sont atteints, mois par mois (si c’est la période choisie), pour chacun des services. Ce tableau servira de support de communication auprès de la direction pour demander :
- des recrutements : “nous avons bien affiné nos objectifs, mais nous n’avons pas pu en respecter certains car nous manquons de personnel”
- des compromis : “maintenir le service X à un niveau de fiabilité satisfaisant nous demande beaucoup de travail et nous empêche de passer ce temps sur d’autres services à forte valeur ajoutée (et de respecter leurs SLO), est ce qu’il est toujours pertinent d’un point de vue business ?”
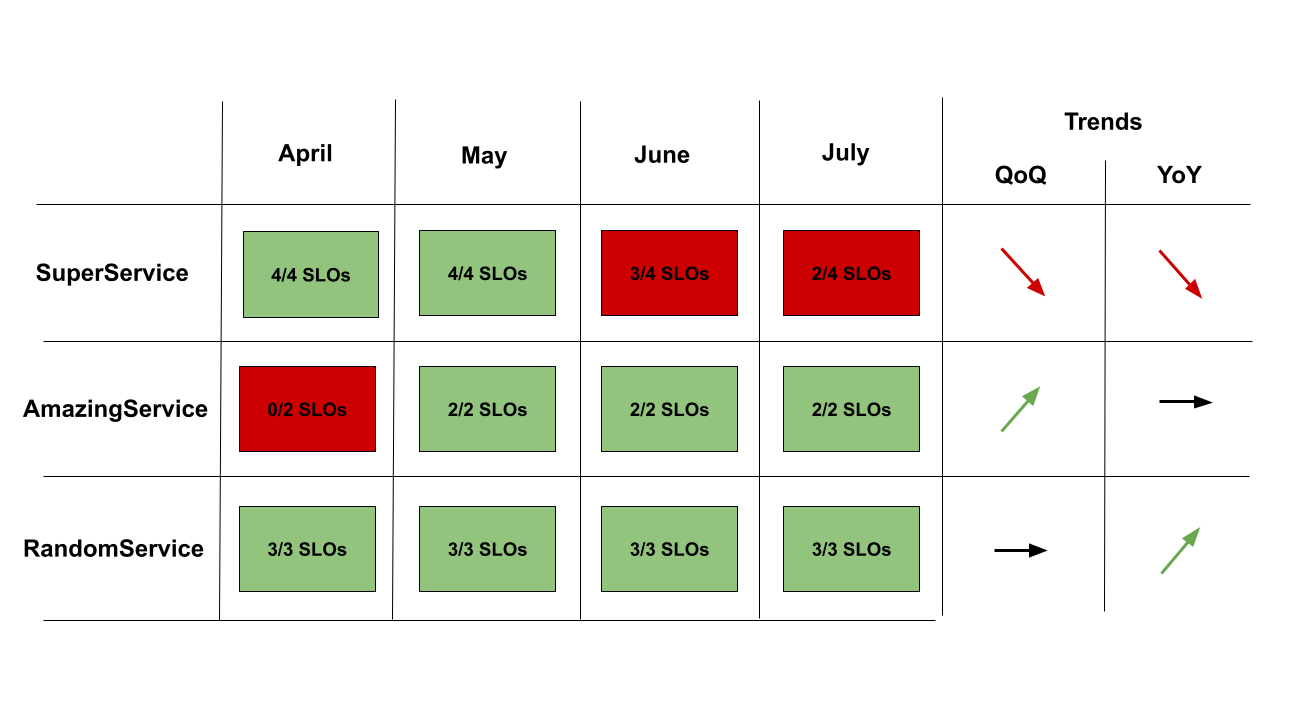
Redéfinir la notion de fiabilité
Il existe plusieurs définitions de la fiabilité (notamment dans le cadre juridique). L’une d’elle a été proposée par l’UTE: “la fiabilité est l’aptitude d’un dispositif à accomplir une fonction requise dans des conditions données pour une période de temps donnée”. Dans ce cadre on se rend compte qu’il est possible de définir les conditions pour estimer que le dispositif (ou système dans notre cas) a bien rempli sa mission dans la dite période.
Puisque l’IT doit baisser ses émissions de gaz à effets de serre de 45% dans les 10 prochaines années si l’on veut espérer atteindre les objectifs des accords de Paris, il me semble capital qu’un système numérique ne soit considéré fiable, que si les conditions de validation de cette fiabilité incluent des objectifs concernant ses émissions de gaz à effet de serre.
Peut-on dire que l’on satisfait durablement le client si l’on contribue à rendre le monde dans lequel il vivra en 2050 encore plus incertain qu’aujourd’hui ?
La méthode SRE fait de plus en plus d’adeptes et fournis un cadre de travail réellement intéressant, car elle encourage une collaboration entre les équipes techniques et le métier. Comme l’a très justement rappelé Alexis Nicolas dans son retour d’expérience à Frug’agile, lutter pour amortir le changement climatique est comme un escape game dont nous faisons tous partie, qu’on le veuille ou non.
Si je suis dans un escape game dans lequel l’échec signifie un réel danger pour mon entourage et moi-même (ce qui est le cas dans celui-ci), je préférerai avoir une aide dynamique pour résoudre les énigmes, des alertes automatisées si je perds trop de temps sur les mauvais éléments et une équipe qui collabore en toute transparence et qui soit pleinement concentrée sur le même objectif. Pas vous ?
Comment obtenir ces métriques ?
Comment avoir des métriques dynamiques, comparables, mises à jour régulièrement, concernant l’impact climatique d’un service numérique ? Comment mesurer le résultat de ses efforts sur le sujet ? Il y a des sujets majeurs concernant cet impact pour lesquels avoir des métriques dynamiques est très compliqué (les experts de l’ACV en savent quelque chose): le coût environnemental et climatique de la fabrication des terminaux qui seront client du service, celui de la fabrication des serveurs et du réseau, celui de la fabrication et de l’entretien des datacenters et des infrastructures, la quantité de fioul brulée dans l’année pour assurer la continuité de service dans le datacenter (ou simplement pour éviter que le fioul ne soit bon pour la poubelle) etc.
Il en est d’autres pour lesquels c’est possible dès à présent. La consommation d’énergie finale (ou secondaire) des serveurs et des applications qu’ils hébergent en est une. Il est donc possible, en plus de surveiller et réduire la part de l’impact climatique de son service, liée à la consommation d’énergie finale, d’alimenter en partie le “scope 2” d’une ACV automatiquement.
Scaphandre est une des solutions pour y parvenir. C’est un agent de monitoring open-source, léger, dédié aux métriques de consommation d’énergie finale (électricité), qui s’insère simplement dans une suite de monitoring existante. Il est modulaire et est pensé pour accueillir simplement de nouveaux exporters. L’idée est que c’est l’agent qui s’adapte à votre infrastructure et à vos besoins et non l’inverse. Il permet déjà de stocker les données dans Prometheus, Riemann et bientôt dans Warp10. Ceci vous permet d’avoir toute la souplesse nécessaire par la suite pour définir vos SLI et SLO en rapport avec l’impact climatique de votre service.
On pourra alors aller plus loin et agrémenter ces métriques de consommation en estimant les émissions de GES associées, par exemple en s’appuyant sur une API comme co2signal, un autre produit de Tomorrow, également à l’origine d’ElectricityMap.
Conclusion
De cette manière on peut calculer la consommation et les émissions estimées, par requête ou par utilisateur (en associant les métriques de monitoring/APM usuelles et les métriques de consommation/émission), puis mettre en place des SLO tels que :
- 95% des requêtes sur l’API entrainent moins de 0.4g eCO2, sur un mois
- 98% des utilisateurs entrainent une consommation cumulée inférieure à 200 Wh sur le mois
Les chiffres sont ici complètement arbitraires et ne veulent pas dire grand chose hors contexte. Mais traquer des indicateurs de ce type, définis conjointement suite à une analyse de l’impact global, me semble être une stratégie efficace pour réduire l’empreinte des services numériques dans la durée. Cette approche est évidemment complémentaire des ACV et d’un bilan carbone complet prenant en compte les aspects matériels que l’on ne peut bien souvent pas mesurer automatiquement.
Je pense cependant que le rôle de la conception et de l’implémentation des services n’est pas à sous-estimer concernant la réduction de l’empreinte de l’IT. La complexité de ces services est grandissante et l’estimation de leur impact toujours plus inaccessible. Une approche bottom-up comme celle présentée ici est selon moi nécessaire et indispensable (bien que non suffisante) pour permettre une amélioration continue à grande échelle.